LZ77编码简介
LZ77是一个由Abraham Lempel于1977年发表的无损压缩算法,其思想与霍夫曼编码有很大差别。霍夫曼编码主要是用较短的编码代替出现频率较高的字符,用较长的编码代替出现频率较低的字符;LZ77编码的核心思想则是将重复出现的较长字符串(短语),使用较短的、指向前面第一次出现的字符串的标记来代替。标记与原序列之间是一种映射,因此,LZ77算法可以说成是基于字典的算法。
由于Python之中的位操作比较难弄,本文只实现了LZ77的编码解码部分,没有实现将编码内容写入文件、或者解码文件的部分。日后用C实现一遍吧
编码
LZ77算法的编码阶段将原序列分成几个部分。
第一个部分是前向缓冲区(look ahead buffer)。它是一个固定大小的普通数组。在序列编码的过程中,会将缓冲区最前面与后面将要提到的滑动窗口(sliding window)里相同的子序列弹出,进入滑动窗口,输出相应的编码,从源序列中读入后继的内容填充数组直到源序列读尽。
第二个部分是滑动窗口(sliding window)。也是一个固定大小的数组,不过其大小一般比前向缓冲区大很多。滑动窗口接受从前向缓冲区弹出的内容,并试图找到与缓冲区最前面的字串相同的最长字串。如果找到了,就会用指向窗口里子串的标记代替源来的字串。
第三个部分是编码部分。它根据前向缓冲区和滑动窗口运行的结果来生成。
LZ77编码的详细步骤如下。
- 首先,将序列读入前向缓冲区。
指针指向第一个字符,查看是否与前向缓冲区内的第一个字符匹配。如果匹配:
- 设滑动窗口中的这个字符位于D,从这个字符开始,一一对比接下来滑动窗口中的字符与前向缓冲区的字符是否匹配,直到出现不匹配的字符为止。设匹配的字串长度为L,此时前向缓冲区匹配子串的后一个字符是c。
- 指针指向第二个字符,重复搜索,直到窗口尽头。
- 取最终L最大的那次为最终结果。如果始终没有找到匹配,D、L为0,c为缓冲区第一个字符。返回(D, L, c)作为匹配序列的编码。然后从滑动窗口尾部删除L个字符,将前向缓冲区中的这L个匹配字符弹出,推入滑动窗口。
- 从源序列读入数据填充前向缓冲区,重复2,直到读尽数据。
- 将编码通过位操作的方式写入文件流。
纯文字比较难以理解,看图可能更直观:
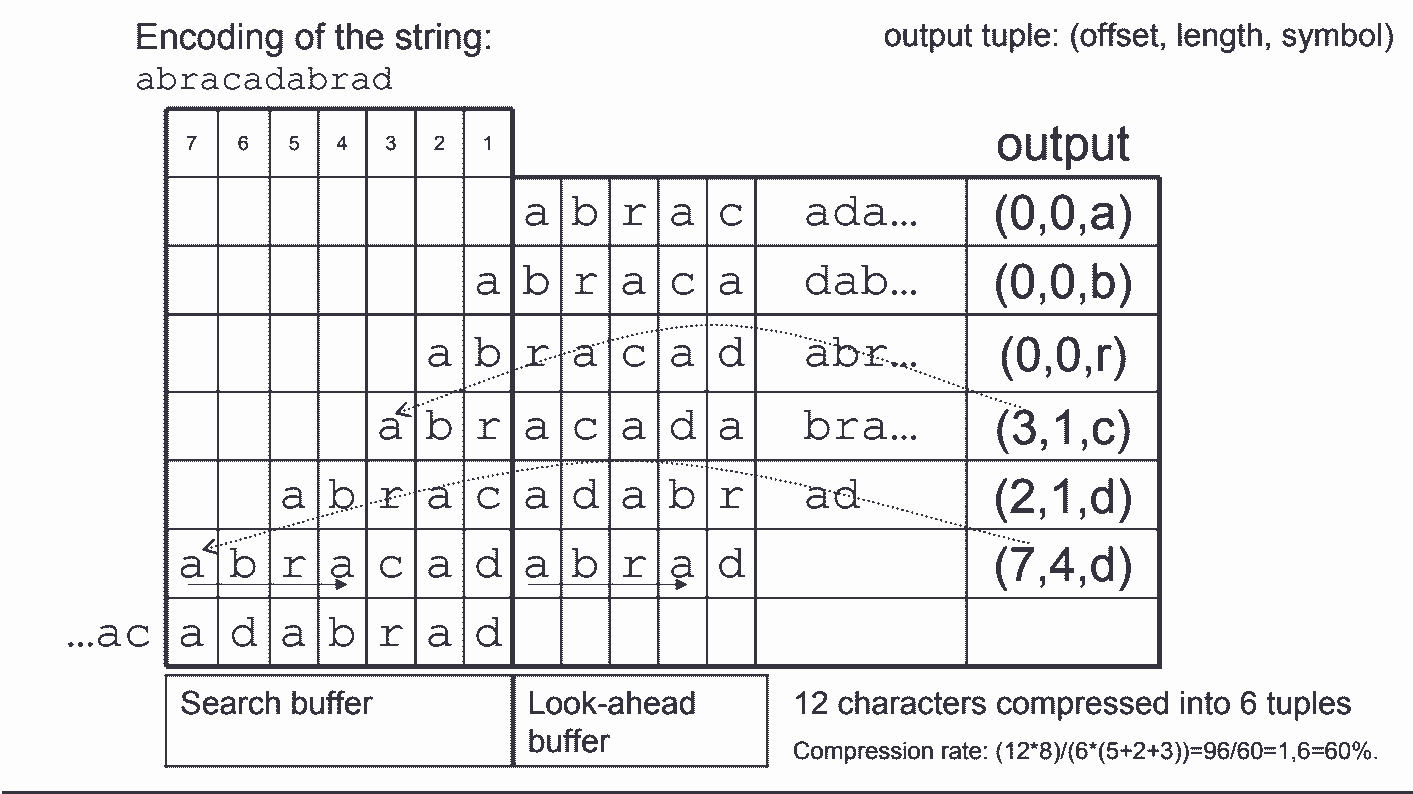
由于会不断在前向缓冲区中搜索匹配的字串,所有编码过程比霍夫曼算法慢
解码
解码过程是编码过程的逆向:
- 将数据读入缓冲区。
- 如果缓冲区头部是普通字符,放入窗口;否则在窗口中搜寻对应字串后,将对应字串放入窗口。返回这个普通字符或字串作为一部分结果。
- 从缓冲区移除相应标记。继续读入。重复第二部直到结束。
实现
https://gist.github.com/Arianxx/d7b4640fe53f4798a4ef1b954c9f28b91
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class LZ77Coding:
SLIDING_WINDOW_SIZE = 4096
LOOKHEAD_BUFFER_SIZE = 32
def search_longest_match(self, data, cursor):
best_position, best_length, next_char = 0, 0, 0
search_index = max(cursor - self.SLIDING_WINDOW_SIZE, 0)
end_buffer_index = min(len(data) - 1,
cursor + self.LOOKHEAD_BUFFER_SIZE - 1)
while search_index < cursor:
if data[search_index] == data[cursor]:
length = 0
while (search_index + length) < cursor \
and (cursor + length) < end_buffer_index:
if data[search_index + length] == data[cursor + length]:
length += 1
else:
break
if length > best_length:
best_position = search_index
best_length = length
next_char = data[cursor + length]
search_index += 1
if not best_length:
next_char = data[cursor]
return best_position, best_length, next_char
def encoding(self, data):
result = []
cursor = 0
while cursor < len(data):
match = self.search_longest_match(data, cursor)
result.append(match)
cursor += max(match[1] + 1, 1)
return result
def decoding(self, data):
result = []
for pair in data:
if not pair[1]:
result.append(pair[2])
else:
chars = result[pair[0]:pair[0] + pair[1]]
result.extend(chars)
result.append(pair[2])
return ''.join(result)